 自猿其说
自猿其说更多题型 语言基础
语言基础 1、C++中虚拟函数的实现机制。 2、指针数组和数组指针的区别。 3、malloc-free和new-delete的区别。 4、sizeof和strlen的区别。 5、描述函数调用的整个过程。 6、C++ STL里面的vector...
语言基础 1、C++中虚拟函数的实现机制。 2、指针数组和数组指针的区别。 3、malloc-free和new-delete的区别。 4、sizeof和strlen的区别。 5、描述函数调用的整个过程。 6、C++ STL里面的vector...
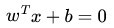
支持向量机 ##第一层、了解SVM 支持向量机,因其英文名为support vector machine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转...

K近邻算法 1.1、什么是K近邻算法 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1时,算法便成了最近邻算法,即寻找最近的那个邻居。...
本章海量数据的习题 1有100W个关键字,长度小于等于50字节。用高效的算法找出top10的热词,并对内存的占用不超过1MB。 提示:老题,与caopengcs讨论后,得出具体思路为: 先把100W个关键字hash映射到小文件,根据题意,1...
倒排索引(Inverted index) 方法介绍 倒排索引是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,常被应用于搜索引擎和关键字查询的问题中。 以英文为例,下面是要被索引的文本: T0 = "i...

Trie树(字典树) 方法介绍 1.1、什么是Trie树 Trie树,即字典树,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是最大限度地减少...
数据库 方法介绍 当遇到大数据量的增删改查时,一般把数据装进数据库中,从而利用数据的设计实现方法,对海量数据的增删改查进行处理。

Bloom Filter 方法介绍 一、什么是Bloom Filter Bloom Filter,被译作称布隆过滤器,是一种空间效率很高的随机数据结构,Bloom filter可以看做是对bit-map的扩展,它的原理是: 当一个元素被加入...

Bitmap 方法介绍 什么是Bit-map 所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。 来看一个具体的例子,假设我们要对...

分布式处理之MapReduce 方法介绍 MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减...
